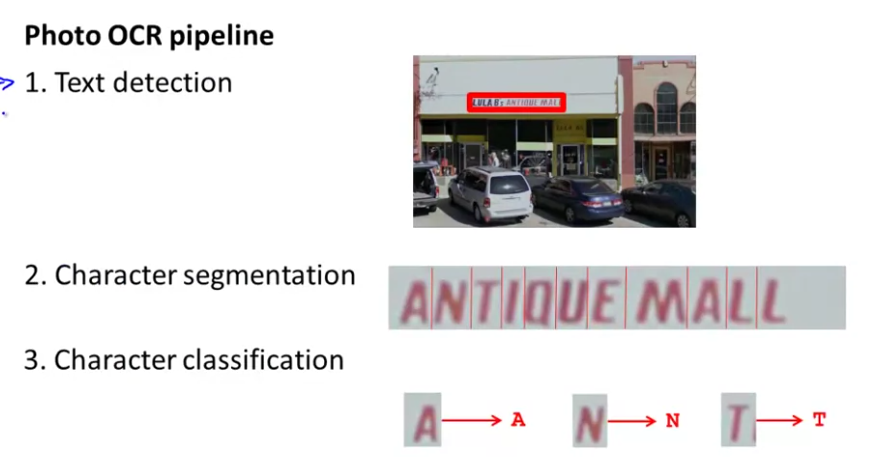
Machine Learning Application - Photo OCR
Pipeline
- Detect text
- Character segmentation
- Character classification
- (Optional) spelling correction.
Sliding Window
- Scan an image step by step to check whether object can be detected in it.
- Draw boundaries around the detected objects/characters.
- Feed these smaller images to the next step.
Character detection
- Train an algorithm which can detect when an image is a the middle of two adjoining characters.
- If it detects image as middle of the two characters, mark it as a boundary.
Artificial data synthesis
- Generate data using off the shelf fonts and other image processing techniques to mimic real world data.
- Use small real world training set, but use image processing techniques, generate more samples.
- Introduce gaussian noise or distortions to generate more samples.
- You need a low bias classifier, so that adding more samples helps.
- If you can get more real world data, that might be better use of resources than spending time on artificial data synthesis.
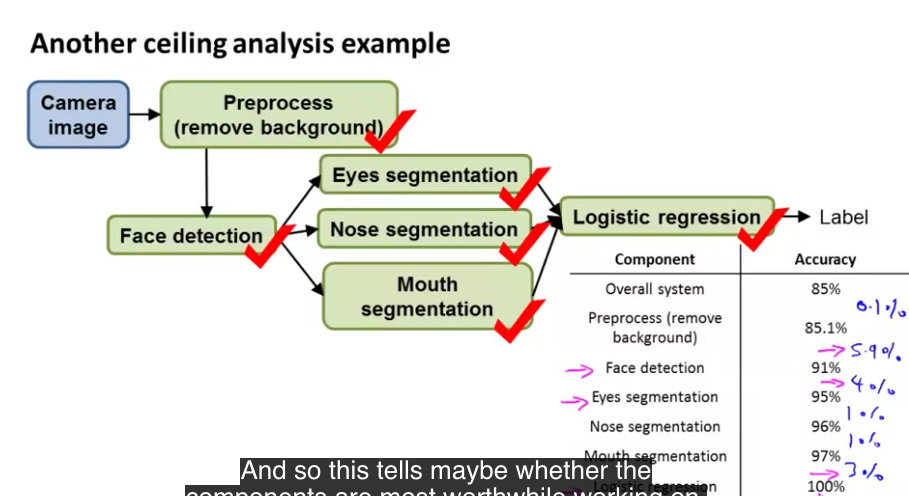
Ceiling Analysis / How to decide which part of the pipeline to work on?
- Mimic a stage is working at 100% accuracy by using training set, but just using label output at the output of the algorithm.
- So if the label is y=1, then algorithm outputs 1, else outputs 0.
- This similar to mocking in classical programming unit testing.
- Step by step mock out each stage of the pipeline and observer the overall pipeline performance in each step.
- If the mock stage which is working at 100% efficiency does not change the overall performance by a lot, then that stage is not worth working on immediate priority.